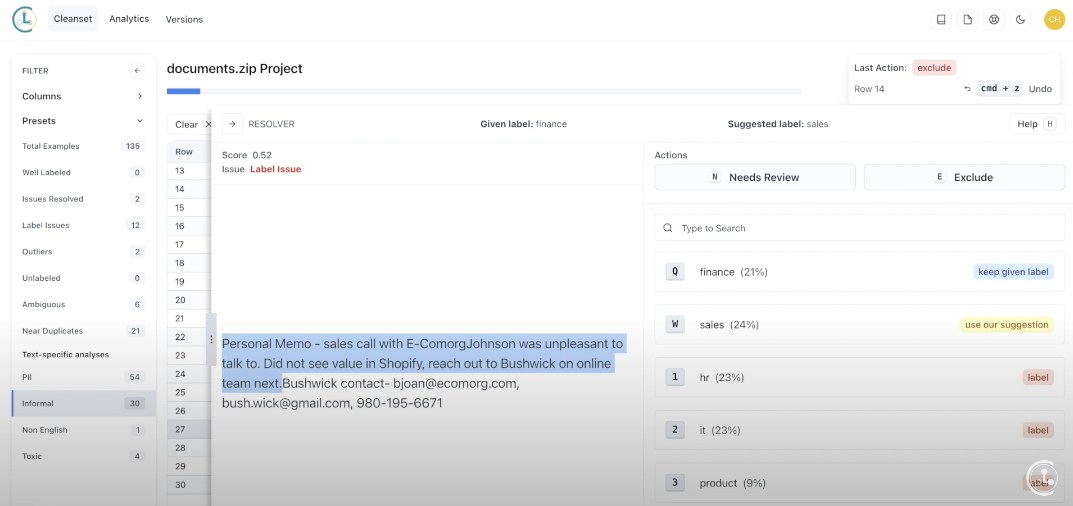
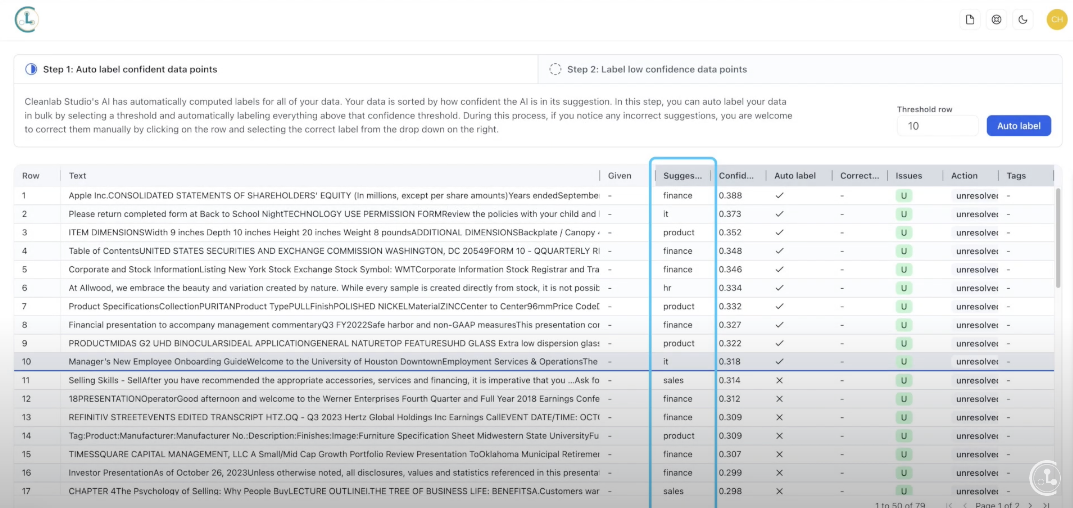
What’s one of the biggest obstacles to standing up a RAG system? A document collection that’s uncurated and riddled with problems. Duplicate information, personally identifiable information, label problems, toxic language, biased/informal language – the list goes on.
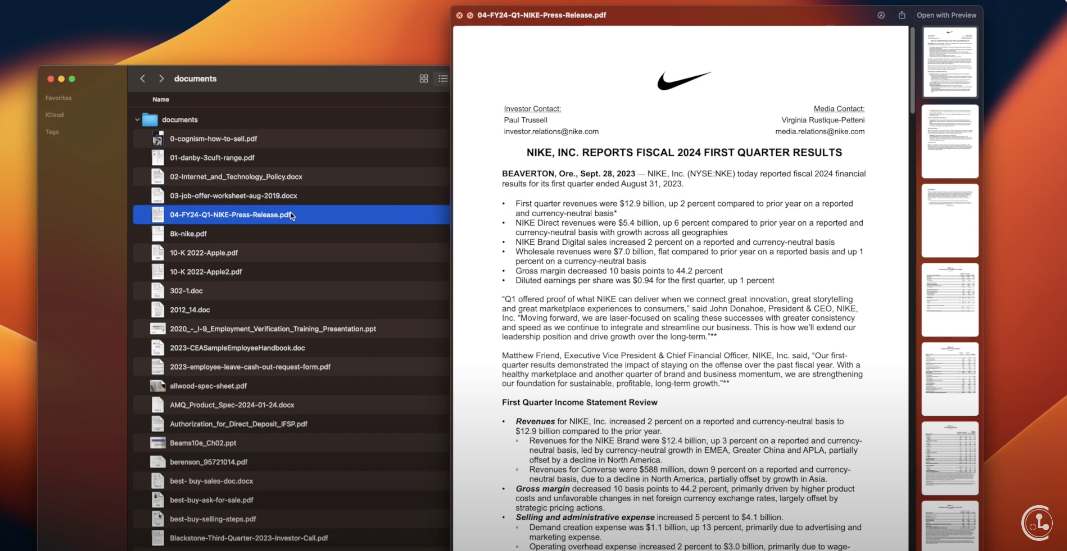
That’s why we’re delighted to announce Document Support - instantly unify large amounts of disparate and unstructured documents into usable auto-curated datasets, with just a few clicks. From the same screen you can deploy a robust and trustworthy model with confidence and without needing to build bespoke pipelines to manage pre-processing.
As a team of Data Scientists ourselves, we know that RAGs are all the rage in 2024 - but going from sandbox to production on a reasonable timeline is the hard part. Our team has focused our efforts on developing cutting edge AI that not only auto-detects and resolves issues across all major datatypes, it can help you label heterogenous data now too. You can leverage our no-code data interface to quickly curate a useful document collection out of your existing materials without spending countless hours and creating manual headaches. Cleanlab Studio now directly supports document collections composed of files of the following types: doc, docx, pdf, ppt, pptx, csv, xls, xlsx - all in the same dataset.
RAG applications aren’t the only document use-case Cleanlab Studio has added enormous value to - check out our solutions pages to learn more about how industry and application agnostic Cleanlab Studio can be. Cleanlab Studio is the one platform a team needs to instantly curate data for a broad range of tasks and deploy better models faster.
Here are some examples to get you started:
-
Watch the demo video: Document Curation for Retrieval Augmented Generation
-
Read the Document Data Quickstart tutorial: Curating Heterogenous Document Datasets
You don’t need a Doc-tor in the house. You just need Cleanlab. Sign up for a free trial.